Astronetes Resiliency Operator provides a transparent and effortless solution to protect Cloud Native platforms from possible disaster outages by leveraging Kubernetes native tools.
This is the multi-page printable view of this section. Click here to print.
Resiliency Operator
- 1: Getting started
- 1.1: Intro
- 1.2: Release notes
- 2: Architecture
- 2.1: Overview
- 2.2: Components
- 2.3: Audit
- 3: Installation
- 4: Configure
- 4.1: Update license key
- 5: Assets
- 5.1: Introduction
- 5.2: Kubernetes clusters
- 5.3: Buckets
- 5.4: Databases
- 6: Synchronization
- 6.1: Introduction
- 6.2: Kubernetes/OpenShift
- 6.2.1: Introduction
- 6.2.2: Configuring a LiveSynchronization
- 6.2.3: Recovering from a Bucket
- 6.2.4: Understanding logging
- 6.2.5: Resynchronization
- 6.2.6: Configuration reference
- 6.2.7: Components
- 6.2.8: Granafa setup
- 6.3: Zookeeper
- 6.3.1: Introduction
- 6.3.2: Configuration
- 7: Automation
- 7.1: Introduction
- 7.2: Plugins
- 7.2.1: Custom image
- 7.2.1.1: Introduction
- 7.2.1.2: Configuration
- 7.2.1.3: Samples
- 7.2.2: Kubernetes object transformation
- 7.2.2.1: Introduction
- 7.2.2.2: Configuration
- 8: Tutorials
- 8.1: Active-active Kubernetes architecture
- 8.2: Active-passive Kubernetes architecture
- 8.3: Synchronize Zookeeper clusters
- 9: API Reference
1 - Getting started
Getting started with Resiliency Operator
1.1 - Intro
What is Resiliency Operator and why it could be useful for you
Astronetes Resiliency Operator is a Kubernetes operator that improves the resiliency of cloud native platforms. It acts as the orchestrator that setup and manages the resiliency of Cloud Native platforms, automating processes and synchronizing data and configurations across multiple technologies.
Astronetes Resiliency Operator helps you to accomplish the following:
- Enable active-active architectures for cloud native platforms
- Automate Disaster Recovery plans for cloud native platforms
Use cases
Active-Active architectures
Active-Active architectures are a proven approach to ensure the required resiliency for mission cricital applications. It protects the application from an outage caused by both technical and operational failures in the platform and its dependencies.
Astronetes Resiliency Operator empowers organizations to deploy and maintain applications across multiple clusters or regions, ensuring maximum uptime and seamless user experiences even during failures or maintenance events.
Disaster Recovery
Business continuity refers to the ability that a particular business can overcome potentially disruptive events with minimal impact in its operations. This no small ordeal requires the definition, implementation of plans, processes and systems while involving complete collaboration and synchronization between multiple actors and departments.
This collection of assets and processes compose the company’s Disaster Recovery. Its goal is to reduce the downtime and data loss in the case of a catastrophic, unforeseen situation. Disaster Recovery needs answer two questions:
- How much data can we lose? - Recovery Point Objective (RPO)
- How long can we take to recover the system? - Recovery Time Objective (RTO)
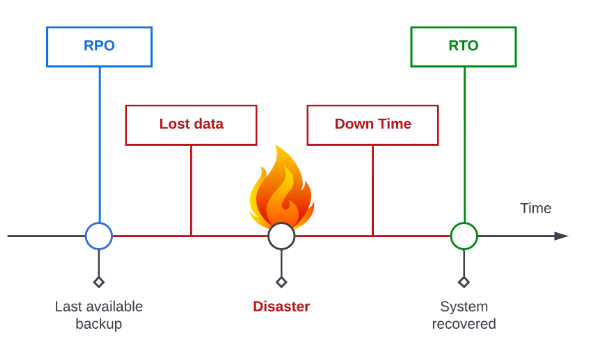
Resiliency Operator provides a solution to improve the business continuity of Cloud Native Platforms by offering a tool that improves resiliency that is transparent in day-to-day operations while having minimal impact in technical maintenance.
Depending on the organisation, system and project necessities resiliency can be improved with a combination of real time synchronization across two or more instances and with a backup and restore strategy. Resiliency Operator implements both methods of data replication across multiple technologies and allows for flexibility on where and how is the information stored.
Business Continuity plans often include complex tests to validate backups content and that they can be restored at any time. To help with these requirements Resiliency Operator includes monitorization systems so that operational teams can make sure that the data is being correctly synchronized and its state in destination.
1.2 - Release notes
Resiliency Operator Release Notes
v1.2.1
- Add custom-image plugin.
2 - Architecture
Astronetes Resiliency Operator architecture
2.1 - Overview
Resiliency Operator architecture
Resiliency Operator acts as the orchestrator that setup and manages the resiliency of Cloud Native platforms, automating processes and synchronizing data and configurations across multiple technologies.
It is built with a set of plugins that enables to integrate many technologies and managed services in the resiliency framework.
Key concepts
Assets
Platforms, technologies and services can be linked to the Resiliency Operator to be included in the resiliency framewor, like Kubernetes clusters and databases.
Synchronizations
The synchronization of data and configurations can be configured according to the platform requirements.
| Synchronization Name | Description |
|---|---|
| Synchronization | Synchronize data and configurations only once. |
| SynchronizationPlan | Synchronize data and configurations based on a scheduled period. |
| LiveSynchronization | Real-time synchronization of data and configurations. |
Automation
The Resiliency Operator allows the automation of tasks to be executed when an incident or a disaster occurs.
2.2 - Components
Resiliency Operator Components
Astronetes Resiliency Operator is software that can be deployed on Kubernetes based clusters. It is composed by a set of controllers that automate and orchestrate the resiliency of Cloud Native platforms.
Operator
| Controllers | Description |
|---|---|
| Bucket | Orchestrate the Bucket obejcts. |
| Database | Orchestrate the Database obejcts. |
| Kubernetes Cluster | Orchestrate the KubernetesCluster obejcts. |
| Live Synchronization | Orchestrate the LiveSynchronization obejcts. |
| Synchronization Plan | Orchestrate the SynchronizationPlan obejcts. |
| Synchronization | Orchestrate the Synchronization obejcts. |
| Task Run | Orchestrate the TaskRun obejcts. |
| Task | Orchestrate the Task obejcts. |
2.3 - Audit
Parameters built into Resiliency Operator to track when a change was made and whom did it
Auditing and version control is an important step when configuring resources. Knowing when a change was made and the account that applied it can be determinative in an ongoing investigation to solve an issue or a configuration mismanagement.
Audit annotations
The following annotation are attached to every resource that belongs to Resiliency Operator Custom Resources:
apiVersion: automation.astronetes.io/v1alpha1
kind: LiveSynchronization
metadata:
annotations:
audit.astronetes.io/last-update-time: "<date>" # Time at which the last update was applied.
audit.astronetes.io/last-update-user-uid: "<uid-hash>" # Hash representing the Unique Identifier of the user that applied the change.
audit.astronetes.io/last-update-username: "<username>" # Human readable name of the user that applied the change.
Example:
apiVersion: automation.astronetes.io/v1alpha1
kind: LiveSynchronization
metadata:
annotations:
audit.astronetes.io/last-update-time: "2024-02-09T14:05:30.67520525Z"
audit.astronetes.io/last-update-user-uid: "b3fd2a87-0547-4ff7-a49f-cce903cc2b61"
audit.astronetes.io/last-update-username: system:serviceaccount:preproduction:microservice1
Fields are updated only when a change to the fields .spec, .labels or .annotations are detected. Status modifications by the operator are not recorded.
3 - Installation
Install the Resiliency Operator
3.1 - Preparing to install
Setup for the necessary tools to install the operator.
Prerequisites
- Get familiarized with the architecture reading this section.
- The Secret provided by AstroKube to access the Image Registry.
- The Secret provided by AstroKube with the license key.
Cluster requiremenets
Supported platforms
Astronetes Resiliency Operator is vendor agnostic meaning that any Kubernetes distribution such as Google Kubernetes Engine, Azure Kubernetes Service, OpenShift or self-managed bare metal installations can run it.
This is the certified compatibility matrix:
| Platform | Min Version | Max Version |
|---|---|---|
| AKS | 1.24 | 1.29 |
| EKS | 1.24 | 1.28 |
| GKE | 1.24 | 1.28 |
| OpenShift Container Platform | 4.11 | 4.14 |
Permissions
To install the Resiliency Operator on a cluster, you need to have Cluster Admin permissions in that cluster.
The Resiliency Operator needs read access to the assets being protected and read/write access to the backup assets. Refer to plugin documentation for details.
Kuberentes requirements
Software
- Official kubernetes.io client CLI kubectl.
Networking
- Allow traffic to the Image Registry quay.io/astrokube using the mechanism provided by the chosen distribution.
OpenShift requirements
Software
- Official OpenShift client CLI.
Networking
- Add quay.io/astrokube to the allowed registries in the Image configuration.
apiVersion: config.openshift.io/v1
kind: Image
metadata:
...
spec:
registrySources:
allowedRegistries:
...
- quay.io/astrokube
3.2 - Installing on OpenShift
Steps to install the Resiliency Operator in OpenShift
The following operations need to executed in both the management and destination cluster.
Prerequisites
- Review the documenation about preparing for the installation.
Process
1. Create Namespace
Create the Namespace where the operator will be installed:
oc create namespace resiliency-operator
2. Setup registry credentials
Create the Secret that stores the credentials to the AstroKube image registry:
oc -n resiliency-operator create -f pull-secret.yaml
3. Setup license key
Create the Secret that stores the license key:
oc -n resiliency-operator create -f license-key.yaml
4. Install the operator
Install the CRDs:
oc apply -f https://astronetes.io/deploy/resiliency-operator/v1.2.1/crds.yaml
Install the operator:
oc -n resiliency-operator apply -f https://astronetes.io/deploy/resiliency-operator/v1.2.1/operator-openshift.yaml
3.3 - Uninstalling on OpenShift
Steps to uninstall the Resiliency Operator on OpenShift
Process
1. Delete Operator objects
Delete the synchronizations from the cluster:
oc delete livesynchronizations.automation.astronetes.io -A --all
oc delete synchronizationplans.automation.astronetes.io -A --all
oc delete synchronizations.automation.astronetes.io -A --all
Delete the assets from the cluster:
oc delete buckets.assets.astronetes.io -A --all
oc delete databases.assets.astronetes.io -A --all
oc delete kubernetesclusters.assets.astronetes.io -A --all
2. Remove the operator
Delete the operator:
oc -n resiliency-operator delete -f https://astronetes.io/deploy/resiliency-operator/v1.2.1/operator-openshift.yaml
Delete the CRDs:
oc delete -f https://astronetes.io/deploy/resiliency-operator/v1.2.1/crds.yaml
3. Remove registry credentials
Delete the Secret that stores the credentials to the AstroKube image registry:
oc -n resiliency-operator delete -f pull-secret.yaml
4. Remove license key
Delete the Secret that stores the license key:
oc -n resiliency-operator delete -f license-key.yaml
4 - Configure
Configure the operator
test
4.1 - Update license key
Steps to update the license key for the Resiliency Operator
There is no need to reinstall the operator when updating the license key.
Process
1. Update the license key
Update the Kubernetes Secret that stores the license key with the new license:
kubectl -n resiliency-operator apply -f new-license-key.yaml
oc -n resiliency-operator apply -f new-license-key.yaml
2. Restart the Resiliency Operator
Restart the Resiliency Operator Deployment to apply the new license:
kubectl -n resiliency-operator rollout restart deployment resiliency-operator-bucket-controller
kubectl -n resiliency-operator rollout restart deployment resiliency-operator-database-controller
kubectl -n resiliency-operator rollout restart deployment resiliency-operator-kubernetescluster-controller
kubectl -n resiliency-operator rollout restart deployment resiliency-operator-livesynchronization-controller
kubectl -n resiliency-operator rollout restart deployment resiliency-operator-synchronization-controller
kubectl -n resiliency-operator rollout restart deployment resiliency-operator-synchronizationplan-controller
kubectl -n resiliency-operator rollout restart deployment resiliency-operator-task-controller
kubectl -n resiliency-operator rollout restart deployment resiliency-operator-taskrun-controller
oc -n resiliency-operator rollout restart deployment resiliency-operator-bucket-controller
oc -n resiliency-operator rollout restart deployment resiliency-operator-database-controller
oc -n resiliency-operator rollout restart deployment resiliency-operator-kubernetescluster-controller
oc -n resiliency-operator rollout restart deployment resiliency-operator-livesynchronization-controller
oc -n resiliency-operator rollout restart deployment resiliency-operator-synchronization-controller
oc -n resiliency-operator rollout restart deployment resiliency-operator-synchronizationplan-controller
oc -n resiliency-operator rollout restart deployment resiliency-operator-task-controller
oc -n resiliency-operator rollout restart deployment resiliency-operator-taskrun-controller
3. Wait for the Pods restart
Wait a couple of minutes until all the Resiliency Operator Pods are restarted with the new license.
5 - Assets
Assets management
Platforms, technologies and services can be linked to the Resiliency Operator to enable process automation and data synchronization.
5.1 - Introduction
Asset introduction
An Asset is any kind of platform, technology or service that can be imported into the operator to improve its resiliency. Assets can include Kubernetes clusters and databases.
Asset types
Kubernetes Cluster
While the system is designed to be compatible with all kinds of Kubernetes clusters, official support and testing are limited to a specific list of Kubernetes distributions. This ensures that the synchronization process is reliable, consistent, and well-supported.
This is the list of officially supported Kubernetes distributions:
| Distribution | Versions |
|---|---|
| OpenShift Container Platform | 4.12+ |
| Azure Kubernetes Service (AKS) | 1.28+ |
| Elastic Kubernetes Service (EKS) | 1.26+ |
| Google Kubernetes Engine (GKE) | 1.28+ |
Buckets
Public cloud storage containers for objects stored in simple storage service.
Databases
| Database | Versions |
|---|---|
| Zookeeper | 3.6+ |
5.2 - Kubernetes clusters
How-to import Kubernetes clusters
Any kind of KubernetesCluster can be imported in the operator. Credentials are stored in Kubernetes secrets from which the KubernetesCluster collection access to connect to the clusters.
Requirements
- The kubeconfig file to access the cluster
Process
1. Create secret
Get the kubeconfig file that can be used to access the cluster, and save it as kubeconfig.yaml.
Then create the Secret with the following command:
kubectl create secret generic source --from-file=kubeconfig.yaml=kubeconfig.yaml
2. Create resource
Define the KubernetesCluster resource with the following YAML, and save it as cluster.yaml:
apiVersion: assets.astronetes.io/v1alpha1
kind: KubernetesCluster
metadata:
name: cluster-1
spec:
secretName: <secret_name>
Deploy the resource with the following command:
kubectl create -f cluster.yaml
5.3 - Buckets
How-to import Buckets
Buckets can be imported in the operator. Credentials are stored in Kubernetes secrets from which the KubernetesCluster collection access to connect to the clusters.
Requirements
- The access key and the secret key to access the bucket
Process
1. Create secret
Store the following file as secret.yaml and substitute the template parameters with real ones.
apiVersion: v1
kind: Secret
metadata:
name: bucket-credentials
stringData:
accessKeyID: <access_key_id>
secretAccessKey: <secret_access_key>
Then create the Secret with the following command:
kubectl -n <namespace_name> apply -f secret.yaml
2. Create resource
Store the following file as bucket.yaml and substitute the template parameters with real ones.
apiVersion: assets.astronetes.io/v1alpha1
kind: Bucket
metadata:
name: <name>
namespace: <namespace>
spec:
generic:
endpoint: storage.googleapis.com
name: <bucket_name>
useSSL: true
secretName: bucket-credentials
Deploy the resource with the following command:
kubectl create -f bucket.yaml
Examples
AWS S3
Secret:
apiVersion: v1
kind: Secret
metadata:
name: bucket-credentials
stringData:
accessKeyID: <access_key_id>
secretAccessKey: <secret_access_key>
Bucket:
apiVersion: assets.astronetes.io/v1alpha1
kind: Bucket
metadata:
name: gcp
spec:
generic:
endpoint: s3.<bucket-region>.amazonaws.com
name: <bucket-name>
useSSL: true
secretName: bucket-credentials
Google Cloud Storage
Secret:
apiVersion: v1
kind: Secret
metadata:
name: bucket-credentials
stringData:
accessKeyID: <access_key_id>
secretAccessKey: <secret_access_key>
Bucket:
apiVersion: assets.astronetes.io/v1alpha1
kind: Bucket
metadata:
name: gcp-bucket
spec:
generic:
endpoint: storage.googleapis.com
name: <bucket-name>
useSSL: true
secretName: bucket-credentials
5.4 - Databases
How-to import Databases
Databases can be imported in the operator. Credentials are stored in Kubernetes secrets from which the KubernetesCluster collection access to connect to the clusters.
Requirements
- The database credentials
Process
Zookeeper
1. Create resource
Define the Database resource with the following YAML, and save it as database.yaml:
apiVersion: assets.astronetes.io/v1alpha1
kind: Database
metadata:
name: zookeeper
spec:
zookeeper:
client:
servers:
- 172.18.0.4:30181
- 172.18.0.5:30181
- 172.18.0.6:30181
Deploy the resource with the following command:
kubectl create -f database.yaml
6 - Synchronization
Assets management
6.1 - Introduction
Synchronization introduction
Synchronization is a critical process that enables the replication of data and configurations across different platform assets. This ensures consistency, integrity and improve the platform resiliency.
Key concepts
Source and destination
Each synchronization has at least two assets:
- Source: the original location or system from which data and configurations are retrived.
- Destination: the destination location or system where data and configurations are applied or updated.
Synchronization periodicity
There are three distinct types of synchronization processes designed to meet different operational needs: Synchronization, SynchronizationPlan, and LiveSynchronization.
Synchronization
The Synchronization process is designed to run once, making it ideal for one-time data alignment tasks or initial setup processes. This type of synchronization is useful when a system or component needs to be brought up-to-date with the latest data and configurations from another source without ongoing updates.
SynchronizationPlan
The SynchronizationPlan process operates similarly to a cron job, allowing synchronization tasks to be scheduled at regular intervals. This type is ideal for systems that require periodic updates to ensure data and configuration consistency over time without the need for real-time accuracy.
LiveSynchronization
LiveSynchronization provides real-time synchronization, continuously monitoring and updating data and configurations as changes occur. This type of synchronization is essential for environments where immediate consistency and up-to-date information are crucial.
This option minimises RPO and RTO due to the minimal amount of data lost before a disaster and the low overhead and wait time to restart operations in the new instance.
Resume
| Periodicity | Description |
|---|---|
| Synchronization | Synchronize data and configurations only once. |
| SynchronizationPlan | Synchronize data and configurations based on a scheduled period. |
| LiveSynchronization | Real-time synchronization of data and configurations. |
Prerequisites
Before initiating the Synchronization process, ensure the following prerequisites are met:
- Both source and destiation systems have been defined as Asset.
- There is a network connectivity between the assets and the operator.
6.2 - Kubernetes/OpenShift
Synchronization across two Kubernetes clusters.
6.2.1 - Introduction
Synchronize Kubernetes/OpenShift clusters
You can synchronize Kubernetes objects between two clusters.
Supported models
LiveSynchronization
The Kubernetes objects are syncrhonized in real-time between the defined clusters using the LiveSynchronization Kubernetes object.
Architecture
The sychronization can be executed from inside one of the clusters you want to synchronize (2-clusters architecture) or from a third clusters (3-clusters architecture).
2-clusters architecture
This configuration is recommended for training, testing, validation or when the 3-clusters option is not optimal or possible.
The currently active cluster will be the source cluster, while the passive is the destination cluster. The operator, including all the Custom Resource Definitions (CRD) and processes, is installed in the latter. The operator will listen for new resources that fulfill the requirements and clone them into the destination cluster.
The source cluster is never aware of the destination cluster and can exist and operate as normal without its presence. The destination cluster needs to have access to it through a KubernetesCluster resource.
3-clusters architecture
In addition of the already existing 2 clusters, this modality includes the management cluster. The operator synchronization workflow is delegated in it instead of depending on the destination cluster. The management cluster is in charge of reading the changes and new resources in the source cluster and syncing them to the destination. Neither source or destination cluster needs to know of the existence of the management cluster and can operate without it. Having a separate cluster that is decoupled from direct production activity lowers operational risks and eases access control to both human and software operators. The operator needs to be installed in the destination cluster as well to start the recovery process without depending on other clusters. Custom Resources that configure the synchronization are deployed in the management cluster while those only relevant when executing the recovery process are deployed in the destination cluster.
This structure fits organizations that are already depending on a management cluster for other tasks or ones that are planning to do so. Resiliency Operator does not require a standalone management cluster and can be installed and managed from an existing one.
6.2.2 - Configuring a LiveSynchronization
How to proctect the platform resources from a disaster
Introduction
A LiveSynchronization resource indicates a set of Kubernetes resource to replicate or synchronize between the source cluster and the destination cluster.
Requirements
- Create a KubernetesCluster resource for the source cluster.
- Create a KubernetesCluster resource for the destination cluster.
Process
1. Configure the live synchronization
Create the livesynchronization.yaml file according to your requirements. For this example, the goal is to synchronize deployments with the disaster-recovery label set to enabled. It is also desirable that when its replication is completed that no pod is created in the destination cluster and that after a recovery is launched the deployment launches active pods again.
Let’s dissect the following YAML:
apiVersion: automation.astronetes.io/v1alpha1
kind: LiveSynchronization
metadata:
name: livesynchronization-sample
spec:
suspend: false
plugin: kubernetes-objects-to-kubernetes
config:
sourceName: source
destinationName: destination
observability:
enabled: false
replication:
resources:
- group: apps
version: v1
resource: deployments
transformation:
patch:
- op: replace
path: /spec/replicas
value: 0
filters:
namespaceSelector:
matchLabels:
disaster-recovery: enabled
recoveryProcess:
fromPatch:
- op: replace
path: /spec/replicas
value: 1
spec.config.sourceName and spec.config.destinationName refers to the name and namespace of the KubernetesCluster resources for the corresponding clusters.
The spec.config.replication.resources is a list of the set of resources to deploy. A single LiveSynchronization can cover multiple types or groups of resources, although this example only manages deployments.
The type of the resource is defined at spec.config.replication.resources[*].resource. The filters can be located in spec.config.replication.resources[*].filters. In this case, the RecoveryPlan is matching the content of the disaster-recovery label.
The spec.config.replication.resources[*].transformation and spec.config.replication.resources[*].recoveryProcess establish the actions to take after each resource is synchronized and after they are affected by the recovery process respectively. In this case, while being replicated, each deployment will set their replicas to 0 in the destination cluster and will get back to one after a successful recovery. The resource parameters are always left intact in the source cluster.
2. Suspending and resumen a recovery plan
A keen eye might have noticed the spec.suspend parameter. In this example it is set to true to indicate that the recovery plan is inactive. An inactive or suspended recovery plan will not replicate new or existing resources until it is resumed. Resuming a recovery plan can be done by setting spec.suspend to false and applying the changes in yaml. Alternatively, a patch with kubectl will work as well and will not require the original yaml file:
kubectl patch livesynchronization <livesynchronization_name> -p '{"spec":{"suspend":false}}' --type=merge
3. Deploy the Live Synchronization
The live synchronizarion can be deployed as any other Kubernetes resource:
kubectl -n <namespace_name> apply -f livesynchronization.yaml
Live Synchronizations and namespaces
It is only possible to deploy one live synchronization per namespace if they share common resources such as a bucket or a kubernetes cluster.Additional steps
For more examples, take a look at our [samples](../../samples/kubernetes-objects-to-kubernetes" >}} “samples”).
Modifying synchronized resources.
Depending on the use case and the chosen solution for Resiliency Operator, it is convenient that resources synchronized in the destination cluster differ from the original copy. Taking as example a warm standby scenario, in order to optimize infrastructure resources, certain objects such as Deployments or Cronjobs do not need to be actively running until there is a disaster. The standby destination cluster can run with minimal computing power and autoscale as soon as the recovery process starts, reducing the required overhead expenditure.
While a resource is being synchronized into the destination cluster, its properties can be transformed to adapt them to the organization necessities. Then, if and when a disaster occurs, the resource characteristics can be restored to either its original state or an alternative one with the established recover process.
Filters
FIlters are useful to select only the exact objects to synchronize. They are set in the spec.config.replication.resources[*].filters parameter.
Name selector
The nameSelector filters by the name of the resources of the version and type indicated. The following example selects only the Configmaps that follow the regular expression config.*:
apiVersion: automation.astronetes.io/v1alpha1
kind: LiveSynchronization
metadata:
name: livesynchronization-sample
spec:
plugin: kubernetes-objects-to-kubernetes
suspend: false
config:
sourceName: source
destinationName: destination
observability:
enabled: false
replication:
resources:
- version: v1
resource: configmaps
filters:
nameSelector:
regex:
- "config.*"
This selector can also be used negatively with excludeRegex. The following example excludes every configmap that ends in .test:
apiVersion: automation.astronetes.io/v1alpha1
kind: LiveSynchronization
metadata:
name: livesynchronization-sample
spec:
plugin: kubernetes-objects-to-kubernetes
suspend: false
config:
sourceName: source
destinationName: destination
observability:
enabled: false
replication:
resources:
- version: v1
resource: configmaps
filters:
nameSelector:
excludeRegex:
- "*.test"
Namespace selector
The namespaceSelector filters resources taking in consideration the namespace they belong to. This selector is useful to synchronize entire applications if they are stored in a namespace. The following example selects every deployment that is placed in a namespace with the label disaster-recovery: enabled:
apiVersion: automation.astronetes.io/v1alpha1
kind: LiveSynchronization
metadata:
name: livesynchronization-sample
spec:
plugin: kubernetes-objects-to-kubernetes
suspend: false
config:
sourceName: source
destinationName: destination
observability:
enabled: false
replication:
resources:
- group: apps
version: v1
resource: deployments
filters:
selector:
matchLabels:
disaster-recovery: enabled
Transformations
Transformations are set in the spec.config.replication.resources[*].transformation parameter and are managed through patches.
Patch modifications alter the underlying object definiton using the same mechanism as kubectl patch. As with jsonpatch, the allowed operations are replace, add and remove. Patches are defined in the spec.config.replication.resources[*].transformation.patch list and admits an arbitary number of modifications.
apiVersion: automation.astronetes.io/v1alpha1
kind: LiveSynchronization
metadata:
name: livesynchronization-sample
spec:
...
config:
...
replication:
resources:
- ...
transformation:
patch:
- op: replace
path: /spec/replicas
value: 0
- op: remove
path: /spec/strategy
Multiple transformations
While Resiliency Operator supports multiple transformations for the same LiveSynchronization, it does not cover having more than one transformation for the same resource group. Transformations that cover different resources of the same resource group should be in different recovery plans. The same resource or resource set can only be affected by up to one transformation and cannot be present in more than one LiveSynchronization.RecoveryProcess
The RecoveryProcess of a LiveSynchronization is executed in the case of a disaster to recover the original status of the application in the destination cluster. A resource can be either restored from the original definition stored in a bucket or by performing custom patches like with Transformations.
To restore from the original data, read the Recovering from a Bucket section. This option will disregard performed transformations and replace the parameters with those of the source cluster.
Patching when recovering is accessible at spec.config.replication.resources[*].recoveryProcess.fromPatch list and admits an arbitary number of modifications. It will act on the current state of the resource in the destination cluster, meaning it will take into consideration the transformations performed when it was synchronized unlike when recovering from original. As with jsonpatch, the allowed operations are replace, add and remove.
apiVersion: automation.astronetes.io/v1alpha1
kind: LiveSynchronization
metadata:
name: livesynchronization-sample
spec:
...
config:
...
replication:
resources:
- ...
recoveryProcess:
fromPatch:
- op: replace
path: /spec/replicas
value: 1
6.2.3 - Recovering from a Bucket
How save objects and recover them using object storage.
Introduction
A Bucket resource indicates an Object Storage that will be used to restore original objects when recovering from a disaster.
Object Storage stores data in an unstructured format in which each entry represents an object. Unlike other storage solutions, there is not a relationship or hierarchy between the data being stored. Organizations can access their files as easy as with traditional hierarchical or tiered storage. Object Storage benefits include virtually infinite scalability and high availability of data.
Many Cloud Providers include their own flavor of Object Storage and most tools and SDKs can interact with them as their share the same interface. Resiliency Operator officially supports the following Object Storage solutions:
AWS Simple Storage Service (S3) Google Cloud Storage
Resiliency Operator can support multiple buckets in different providers as each one is managed independently.
Contents stored in a bucket
A bucket is assigned to a LiveSynchronization by setting it in a spec.config.bucketName item. It stores every synchronized object in the destination cluster with some internal control annotations added. In the case of a disaster, resources with recoveryProcess.fromOriginal.enabled equal to true will be restored using the bucket configuration.
The path of a stored object is as follows: <bucket_namespace>/<bucket_name>/<object_group-version-resource>/<object_namespace>.<object_name>.
Requirements
- At least an instance of a
ObjectStorageservice in one of the supported Cloud Providers. This is commonly known as a bucket and will be referred as so in the documentation. - At least one pair of
accessKeyIDandsecretAccessKeythat gives both write and read permissions over all objects of the bucket. Refer to the chosen cloud provider documentation to learn how to create and extract them. It is recommended that each access key pair has only access to a single bucket.
Preparing and setting the bucket
Create the secret
Store the following file and apply it into the cluster substituting the template parameters with real ones.
apiVersion: v1
kind: Secret
metadata:
name: bucket-credentials
stringData:
accessKeyID: <access_key_id>
secretAccessKey: <secret_access_key>
Create the Bucket
Store the following file and apply it into the cluster substituting the template parameters with real ones.
apiVersion: assets.astronetes.io/v1alpha1
kind: Bucket
metadata:
name: gcp
namespace: <namespace>
spec:
generic:
endpoint: storage.googleapis.com
name: <bucket_name>
useSSL: true
secretName: bucket-credentials
Create the LiveSynchronization
If the LiveSynchronization does not set spec.resources[x].recoveryProcess.fromOriginal.enabled equal to true, where x refers to the index of the desired resource, the contents of the bucket will not be used. For the configuration to work, make sure both the bucket reference and recovery process transformations are correctly set.
Indicating which bucket to use can accomplished by configuring the spec.config.bucketName like in the following example:
apiVersion: automation.astronetes.io/v1alpha1
kind: LiveSynchronization
metadata:
name: livesynchronization-sample
spec:
plugin: kubernetes-objects-to-kubernetes
config:
sourceName: source
destinationName: destination
bucketName: <bucket_object_name>
observability:
enabled: false
replication:
resources:
- group: apps
version: v1
resource: deployments
transformation:
patch:
- op: replace
path: /spec/replicas
value: 0
filters:
namespaceSelector:
matchLabels:
env: pre
recoveryProcess:
fromPatch:
- op: replace
path: /spec/replicas
value: 1
- group: apps
version: v1
resource: deployments
transformation:
patch:
- op: replace
path: /spec/replicas
value: 0
filters:
namespaceSelector:
matchLabels:
env: pre-second
recoveryProcess:
fromPatch:
- op: replace
path: /spec/replicas
value: 1
- group: ""
version: v1
resource: services
filters:
namespaceSelector:
matchLabels:
env: pre
- group: ""
version: v1
resource: services
filters:
namespaceSelector:
matchLabels:
env: pre-second
- group: ""
version: v1
resource: secrets
filters:
namespaceSelector:
matchLabels:
env: pre
Create the secret
Store the following file and apply it into the cluster substituting the template parameters with real ones.
apiVersion: v1
kind: Secret
metadata:
name: bucket-credentials
stringData:
accessKeyID: <access_key_id>
secretAccessKey: <secret_access_key>
Create the Bucket
Store the following file and apply it into the cluster substituting the template parameters with real ones.
S3 requires that the region in the endpoint matches the region of the target bucket. It has to be explicitely set as AWS does not infer buckets region e.g. us-east-1 for North Virginia.
apiVersion: assets.astronetes.io/v1alpha1
kind: Bucket
metadata:
name: gcp
spec:
generic:
endpoint: s3.<bucket-region>.amazonaws.com
name: <bucket-name>
useSSL: true
secretName: bucket-credentials
Create the LiveSynchronization
If the Recovery Plan does not set spec.resources[x].recoveryProcess.fromOriginal.enabled equal to true, where x refers to the index of the desired resource, the contents of the bucket will not be used. For the configuration to work, make sure both the bucket reference and recovery process transformations are correctly set.
Indicating which bucket to use can accomplished by configuring the spec.BucketRef like in the following example:
apiVersion: automation.astronetes.io/v1alpha1
kind: LiveSynchronization
metadata:
name: livesynchronization-sample
spec:
plugin: kubernetes-objects-to-kubernetes
config:
sourceName: source
destinationName: destination
bucketName: <bucket_object_name>
observability:
enabled: false
replication:
resources:
- group: apps
version: v1
resource: deployments
transformation:
patch:
- op: replace
path: /spec/replicas
value: 0
filters:
namespaceSelector:
matchLabels:
env: pre
recoveryProcess:
fromPatch:
- op: replace
path: /spec/replicas
value: 1
- group: apps
version: v1
resource: deployments
transformation:
patch:
- op: replace
path: /spec/replicas
value: 0
filters:
namespaceSelector:
matchLabels:
env: pre-second
recoveryProcess:
fromPatch:
- op: replace
path: /spec/replicas
value: 1
- group: ""
version: v1
resource: services
filters:
namespaceSelector:
matchLabels:
env: pre
- group: ""
version: v1
resource: services
filters:
namespaceSelector:
matchLabels:
env: pre-second
- group: ""
version: v1
resource: secrets
filters:
namespaceSelector:
matchLabels:
env: pre
6.2.4 - Understanding logging
How to interpret Disaster Recovery Operator log messages and manage them
Disaster Recovery Operator implements a logging system throughout all its pieces so that the end user can have visibility on the system.
JSON fields
| Name | Description |
|---|---|
| level | Log level at write time. |
| timestamp | Time at which the log was written. |
| msg | Log message. |
| process | Information about the process identity that generated the log. |
| event | Indicates if the log is referring to a create, update or delete action. |
| sourceObject | Object related to the source cluster that is being synchronized. |
| oldSourceObject | Previous state of the sourceObject. Only applicable to update events. |
| sourceCluster | Information about the source managed cluster. |
| destinationObject | Object related to the destination cluster. |
| destinationObject | Information about the destination managed cluster. |
| bucket | Recovery bucket information. |
| bucketObject | Path to the object to synchronize. |
| lastUpdate | Auditing information. More information. |
Examples
An object read from the source cluster.
{
"level": "info",
"timestamp": "2023-11-28T18:05:26.904276629Z",
"msg": "object read from cluster",
"process": {
"id": "eventslistener"
},
"sourceCluster": {
"name": "source",
"namespace": "dr-config",
"resourceVersion": "91015",
"uid": "3c39aaf0-4216-43a8-b23c-63f082b22436"
},
"sourceObject": {
"apiGroup": "apps",
"apiVersion": "v1",
"name": "nginx-deployment-five",
"namespace": "test-namespace-five",
"resource": "deployments",
"resourceVersion": "61949",
"uid": "5eb6d1d1-b694-4679-a482-d453bcd5317f"
},
"oldSourceObject": {
"apiGroup": "apps",
"apiVersion": "v1",
"name": "nginx-deployment-five",
"namespace": "test-namespace-five",
"resource": "deployments",
"resourceVersion": "61949",
"uid": "5eb6d1d1-b694-4679-a482-d453bcd5317f"
},
"lastUpdate": {
"time": "2023-11-25T13:12:28.251894531Z",
"userUID": "165d3e9f-04f4-418e-863f-07203389b51e",
"username": "kubernetes-admin"
},
"event": {
"type": "update"
}
}
An object was uploaded to a recovery bucket.
{
"level": "info",
"timestamp": "2023-11-28T18:05:27.593493962Z",
"msg": "object uploaded in bucket",
"sourceObject": {
"apiGroup": "apps",
"apiVersion": "v1",
"name": "helloworld",
"namespace": "test-namespace-one",
"resource": "deployments",
"resourceVersion": "936",
"uid": "7c2ac690-3279-43ca-b14e-57b6d57e78e1"
},
"oldSourceObject": {
"apiGroup": "apps",
"apiVersion": "v1",
"name": "helloworld",
"namespace": "test-namespace-one",
"resource": "deployments",
"resourceVersion": "936",
"uid": "7c2ac690-3279-43ca-b14e-57b6d57e78e1"
},
"process": {
"id": "processor",
"consumerID": "event-processor-n74"
},
"bucket": {
"name": "bucket-dev",
"namespace": "dr-config",
"resourceVersion": "91006",
"uid": "47b50013-3058-4283-8c0d-ea3a3022a339"
},
"bucketObject": {
"path": "dr-config/pre/apps-v1-deployments/test-namespace-one.helloworld"
},
"lastUpdate": {
"time": "2023-11-25T13:12:29.625399813Z",
"userUID": "165d3e9f-04f4-418e-863f-07203389b51e",
"username": "kubernetes-admin"
}
}
Managing logs
Messages structure vary depending on the operation that originated it.
The sourceCluster and destinationCluster are only present for operations that required direct access to either cluster. For the former, only messages originating from either the eventsListener, processor or reconciler services can include it in their logs. The latter will only be present in synchronizer or reconciler logs messages. These parameters will not be present for internal messages such as those coming from the nats since there is no direct connection with either cluster.
oldSourceObject is the previous state of the object when performing an update operation. It is not present in other types.
When the bucket and bucketObject parameters are present, the operation is performed against the indicated bucket without any involvement of the source and destination clusters. For create operations, an object was uploaded for the first time to the bucket, for updates an existing one is modified and for delete an object was deleted from the specified bucket.
These characteristics can be exploited to improve log searches by narrowing down the messages to those that are relevant at the moment. Serving as an example, the following command will output only those logs that affect the source managed cluster by filtering the messages that lack the sourceCluster.
kubectl -n dr-config logs pre-eventslistener-74bc689665-fwsjc | jq '. | select(.sourceCluster != null)'
This could be useful when trying to debug and solve connection issues that might arise.
Log messages
The log message is located in the msg parameter. It can be read and interpreted to establish the severity of the log. The following tables group every different log message depending on whether it should be treated as error or informative.
Error messages
| msg |
|---|
| “error reading server groups and resources” |
| “error reading resources for group version” |
| “error getting namespace from cluster” |
| “error creating namespace in cluster” |
| “error getting object from cluster” |
| “error creating object in cluster” |
| “error updating object in cluster” |
| “error listing objects in cluster” |
| “error deleting object in cluster” |
| “error uploading object in bucket” |
| “error deleting object form bucket” |
| “error getting object from bucket” |
Informative messages
Not found objects are not errors
Errors regarding not found objects do not represent errors but rather normal behaviour while synchronizing objects not present in one of the clusters.| msg |
|---|
| “reading server groups and resources” |
| “server group and resources read from cluster” |
| “reading resources for group version” |
| “resource group version not found” |
| “group resource version found” |
| “reading namespace from cluster” |
| “namespace not found in cluster” |
| “namespace read from cluster” |
| “creating namespace from cluster” |
| “namespace already exists in cluster” |
| “namespace created in cluster” |
| “reading object from cluster” |
| “object not found in cluster” |
| “object read from cluster” |
| “creating object in cluster” |
| “object created in cluster” |
| “updating object in cluster” |
| “object updated in cluster” |
| “deleting object in cluster” |
| “object deleted in cluster” |
| “listing objects in cluster” |
| “list objects not found in cluster” |
| “listed objects in cluster” |
| “uploading object in bucket” |
| “object uploaded in bucket” |
| “deleting object from bucket” |
| “object deleted from bucket” |
| “getting object from bucket” |
| “object got from bucket” |
| “listing object from bucket” |
6.2.5 - Resynchronization
Synchronized resources reconciliation between source and destination cluster.
Introduction
Due to particular circumstances it might be possible that there are objects that were not synchronized from the source cluster to the destination cluster. To cover this case, Resiliency Operator offers a reconciliation process that adds, deletes or updates objects in the destination cluster if its state differs from the source.
Auto pruning
The resynchronization process will delete resources in the destination cluster that are not present in the source cluster. It is recommended that before recovering from a disaster the target LiveSynchronization is suspended to avoid potential data loss.Architecture
Reconciliation is performed at the LiveSynchronization level. Every Live Synchronization is in charge of their covered objects and that they are up to date with the specification. Reconciliation is started by two components, EventsListener and Reconciler. The former is in charge of additive reconciliation and the latter of substractive reconciliation.
Additive reconciliation
Refers to the reconciliation of missing objects that are present in the source cluster but, for any reason, are not present or are not up to date in the destination cluster. The entry point is the EventsListener service which receives events with the current state in the source cluster of all the objects covered by the Recovery Plan with a period of one hour by default.
These resync events are then treated like regular events and follow the syncronization communication flow. If the object does not exist in the destination cluster, the Synchronizer will apply it. In the case of updates, only those with a resourceVersion greater than the existing one for that object will be applied, updating the definition of said object.
Substractive reconciliation
In the case that an object was deleted in the source cluster but it was not in the destination, the Additive Reconciliation will not detect it. The source cluster can send events containing the current state of its existing components, but not of those that ceased to exist in it.
For that, the Reconciler is activated with a period of one hour by default. It compares the state of the objects covered the Recovery Plan in both source and destination clusters. If a change is found, it creates a delete event in the NATS. This event is then processed as an usual delete event throughout the rest of the communication process.
Modifying the periodic interval
By default, the resynchronization process will be launched every hour. It can be changed by modifying the value at spec.config.resyncPeriod in the LiveSynchronization object. The admitted format is %Hh%Mm%Ss e.g. 1h0m0s for intervals of exactly one hour. Modifying this variable updates the schedule for both additive and substractive reconciliations.
apiVersion: automation.astronetes.io/v1alpha1
kind: LiveSynchronization
metadata:
name: resync-3h-25m-12s
spec:
...
config:
replication:
resyncPeriod: 3h25m12s
6.2.6 - Configuration reference
Plugin parameters and accepted values
LiveSynchronization
Configuration
| Name | Description | Type | Required |
|---|---|---|---|
| sourceName | Kubernetes Cluster acting as source | string | yes |
| destinationName | Kubernetes Cluster acting as destination | string | yes |
| bucketName | Bucket name to upload the synchronization contents | string | no |
| replication | Configuration of the plugin synchronization | UserConfig | yes |
| observability | Configuration of the observability components | ObservabilityConfig | no |
| components | Plugin component management | Components | no |
UserConfig
| Name | Description | Type | Required |
|---|---|---|---|
| resyncPeriod | Period to activate resynchronization | Timestamp with (HH)h(mm)m(ss)s format | no |
| resources | Resources to synchronize | List of Resource | yes |
| forceNamespaceCreation | Force namespace creation when applying the object | boolean | no |
Resource
| Name | Description | Type | Required |
|---|---|---|---|
| group | Group of the resource | string | no |
| version | Version of the resource | string | yes |
| resource | Kind of the resource | string | yes |
| transformation | Transformations to apply | Transformation | no |
| filters | Filters to apply | Filters | no |
| recoveryProcess | Actions to execute while recovering | RecoveryProcess | no |
Transformation
| Name | Description | Type | Required |
|---|---|---|---|
| patchOptions | Patch options | PatchOpts | no |
| patch | Patches to apply | List of PatchOperation | no |
PatchOpts
| Name | Description | Type | Required |
|---|---|---|---|
| skipIfNotFoundOnDelete | Determines if errors should be ignored when trying to remove an field that doesn’t exist. | bool | no |
PatchOperation
| Name | Description | Type | Required |
|---|---|---|---|
| op | Operations to apply. Accepted values are “replace” and “delete” | string | yes |
| path | Path of the object to modify | string | yes |
| value | Value to include if applicable | JSON | yes |
Filters
| Name | Description | Type | Required |
|---|---|---|---|
| selector | Resource selector | Kubernetes LabelSelector | no |
| namespaceSelector | Resource selector based on namespaces | Kubernetes LabelSelector | no |
RecoveryProcess
| Name | Description | Type | Required |
|---|---|---|---|
| patchOptions | Patch options | PatchOpts | no |
| fromPatch | Path of the object to modify | List of PatchOperation | no |
| fromOriginal | Options to recover from a disaster from the original source | From Original | no |
FromOriginal
| Name | Description | Type | Required |
|---|---|---|---|
| enabled | Enable recovering from original | boolean | no |
ObservabilityConfig
| Name | Description | Type | Required |
|---|---|---|---|
| enabled | Enable observability | boolean | no |
| interval | Interval to gather metrics from source | Duration with format number and metric e.g. 30s or 15m | no |
Components
| Name | Description | Type | Required |
|---|---|---|---|
| eventsListener | Settings for the component | Component | no |
| processor | Settings for the component | Component | no |
| reconciler | Settings for the component | Component | no |
| restorer | Settings for the component | Component | no |
| synchronizer | Settings for the component | Component | no |
| nats | Settings for the component | Component | no |
| redis | Settings for the component | Component | no |
| metricsExporter | Settings for the component | Component | no |
Component
| Name | Description | Type | Required |
|---|---|---|---|
| logLevel | Log level for the component | string | no |
| imagePullPolicy | Image pull policy for the component image | Kubernetes pull policy | no |
| resources | Resource quota for the component | Kubernetes Resource Quotas | no |
| concurrentTasks | Number of concurrent tasks | int32 | no |
| replicas | Number of replicas | int32 | no |
6.2.7 - Components
Kubernetes to Kubernetes plugin Components
Synchronization across clusters is managed through Kubesync, Astronetes solution for Kubernetes cluster replication. The following components are deployed when synchronization between two clusters is started:
| Component | Description | Source cluster permissions | Destination cluster permissions |
|---|---|---|---|
| Events listener | Read events in the source cluster. | Cluster reader | N/A |
| Processor | Filter and transform the objects read from the source cluster. | Cluster reader | N/A |
| Synchronizer | Write processed objects in the destination cluster. | N/A | Write |
| Reconciler | Sends delete events whenever it founds discrepancies between source and destination. | Cluster reader | Cluster reader |
| NATS | Used by other components to send and receive data. | N/A | N/A |
| Redis | Stores metadata about the synchronization state. Most LiveSynchronization components interact with it. | N/A | N/A |
| Metrics exporter | Export metrics about the LiveSynchronization status. | N/A | N/A |
6.2.8 - Granafa setup
How to configure Grafana
Resiliency Operator offers the option of leveraging an existing Grafana installation to monitor the state of the synchronization and recovery process. Users can incorporate the provided visualizations to their workflows in a transparent manner without affecting their operability.
Prerequisites
Grafana Operator
The operator installation includes the necessary tools to extract the information from it. To view that information with the official dashboard, is required that the management cluster has the Grafana Operator installed.
Process
Create the Dashboard
Create the GrafanaDashboard from the release manifests:
kubectl apply -f https://astronetes.io/deploy/disaster-recovery-operator/v1.2/grafana-v5-dashboard.yaml
Working with the dashboard
The dashboard shows detailed information about the write, read and computing processes alongside a general overview of the health of the operator.
General view of the status of the operator:
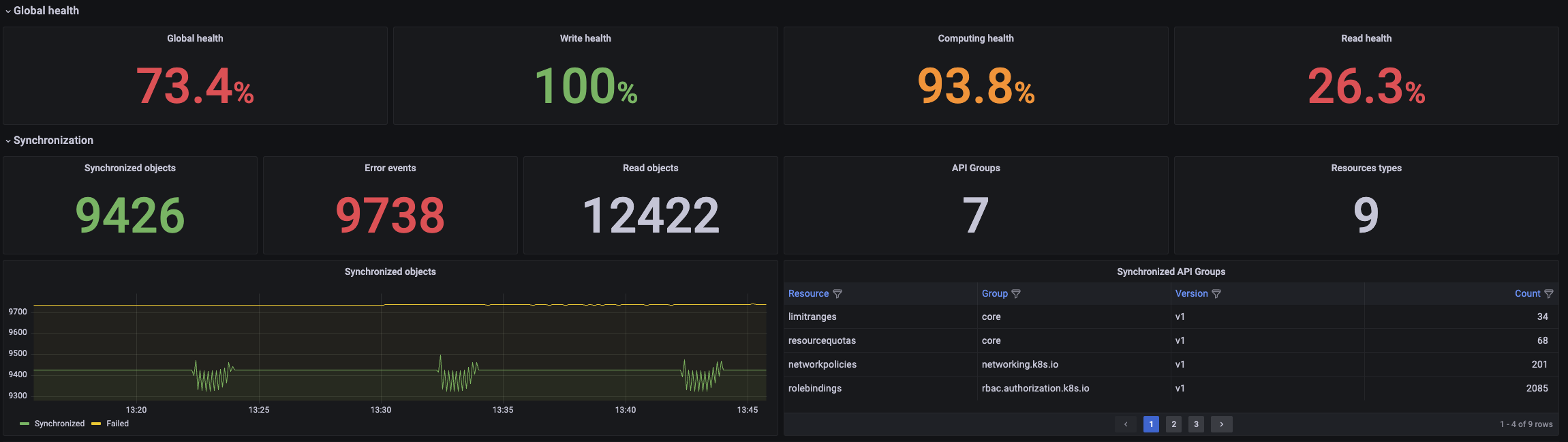
The dashboard can be filtered attending the following characteristics:
- Namespace. Only shows information related to the
LiveSynchronizationsin a specified namespace. - Recovery Plan. Filters by a specific
LiveSynchronizaton. - Object Namespace. Only shows information of the objects located in a given namespace regardless their associated
LiveSynchronization. - Object API Group. Objects are filtered attending to the API Group that they belong to.
Filters can be combined to get more specific results e.g. Getting the networking related objects that belong to a LiveSynchronization that is deployed in a namespace.
6.3 - Zookeeper
Synchronize Zookeeper data between clusters
6.3.1 - Introduction
Synchronize Zookeeper data between clusters
You can synchronize Zookeeper data between two clusters using the Zookeeper protocol.
Supported models
One time synchronization
You can synchronize the data just once with the Synchronization Kubernetes object.
Periodic synchronization
You can synchronize periodically the SynchronizationPlan Kubernetes object.
Samples
Synchronize once
Synchronize the data once only in the /test path:
apiVersion: automation.astronetes.io/v1alpha1
kind: Synchronization
metadata:
generateName: synchronize-zookeeper-
spec:
plugin: zookeeper-to-zookeeper-nodes
config:
sourceName: zookeeper-source
destinationName: zookeeper-destination
rootPath: /test
createRoutePath: true
Scheduled synchronization
Synchronize data every hour in the /test path:
apiVersion: automation.astronetes.io/v1alpha1
kind: SynchronizationPlan
metadata:
name: synchronize-zookeeper
spec:
schedule: "0 * * * *"
template:
spec:
plugin: zookeeper-to-zookeeper-nodes
config:
sourceName: zookeeper-source
destinationName: zookeeper-destination
rootPath: /test
6.3.2 - Configuration
Plugin parameters and accepted values
Synchronization
Configuration
| Name | Description | Type | Required |
|---|---|---|---|
| sourceName | Zookeeper instance acting as source | string | yes |
| destinationName | Zookeeper instance acting as destination | string | yes |
| rootPath | Root Path of the contents to synchronize | string | yes |
| createRootPath | Whether to create the Root Path in the destination database | boolean | no |
| ignoreEphemeral | Whether to ignore ephemeral | boolean | no |
| excludePathRegexp | Regular expression for keys to exclude while synchronizing | string | no |
7 - Automation
Incident response automation
7.1 - Introduction
Automation introdution
The operations to improve the platform resiliency can be automated with the automation framework provided by the Resiliency Operator.
Use cases
Recovery from a disaster
After a disaster occurs in one of your platform assets, the automation framework help in the recovery of the platform.
Key concepts
Tasks
A Task represents a configurable, reusable unit of work. It defines a plugin with a specific configuration to be executed later.
TaskRuns
A TaskRun represents a single execution of a Task. When a TaskRun is created, it triggers the execution of the plugin defined in the Task.
7.2 - Plugins
Automation plugins
7.2.1 - Custom image
Run custom container image in Kubernetes cluster.
7.2.1.1 - Introduction
Custom image plugin introduction
The custom-image plugins enables the deployment of a custom image to be executed as Task. This is extremely useful to run custom logic and software in the resiliency patterns.
The Pod is deployed in the Kubernetes namespace where the Task has been created.
7.2.1.2 - Configuration
Plugin parameters and accepted values
Task
Configuration
| Name | Description | Type | Required |
|---|---|---|---|
| image | Container image to be deployed | string | yes |
| command | The command to be executed when the container starts | []string | yes |
7.2.1.3 - Samples
Kubernetes to Kubernetes plugin Architecture
This is a list of samples of what can be perfomed as Task with the custom-image plugin.
Bash command
Run a bash command:
apiVersion: automation.astronetes.io/v1alpha1
kind: Task
metadata:
name: hello-world
spec:
plugin: custom-image
config:
image: busybox
command:
- echo
- "hello world"
Kubectl command
Execute a kubectl command:
apiVersion: automation.astronetes.io/v1alpha1
kind: Task
metadata:
name: kubectl
spec:
plugin: custom-image
config:
image: bitnami/kubectl:1.27
command:
- kubectl
- cluster-info
clusterRole: cluster-admin
7.2.2 - Kubernetes object transformation
Transform objects in a Kubernetes cluster.
7.2.2.1 - Introduction
Plugin introduction
The custom-image plugins enables the deployment of a custom image to be executed as Task. This is extremely useful to run custom logic and software in the resiliency patterns.
7.2.2.2 - Configuration
Plugin parameters and accepted values
Task
Configuration
| Name | Description | Type | Required |
|---|---|---|---|
| image | Container image to be deployed | string | yes |
| command | The command to be executed when the container starts | []string | yes |
8 - Tutorials
Tutorials for real-world use cases
8.1 - Active-active Kubernetes architecture
How to setup an active-active architecture between two Kubernetes clusters
Overview
Active-active replication between Kubernetes clusters is a strategy to ensure high availability and disaster recovery for applications. In this setup, multiple Kubernetes clusters, typically located in different geographical regions, run identical copies of an application simultaneously.
Prerequisites
- Install Astronetes Resiliency Operator.
- Create a namespace where to store the secrets and run the synchronization between clusters.
Setup
Import the first cluster
Import the first Kubernetes cluster as described in details here:
Save the kubeconfig file as
cluster-1-kubeconfig.yaml.Import the kubeconfig file as secret:
kubectl create secret generic cluster-1-kubeconfig --from-file=kubeconfig.yaml=cluster-1-kubeconfig.yamlCreate the KubernetesCluster resource manifest
cluster-1.yaml:apiVersion: assets.astronetes.io/v1alpha1 kind: KubernetesCluster metadata: name: cluster-1 spec: secretName: cluster-1-kubeconfigDeploy the resource with the following command:
kubectl create -f cluster-1.yaml
Import the second cluster
Import the first Kubernetes cluster as described in details here:
Save the kubeconfig file as
cluster-2-kubeconfig.yaml.Import the kubeconfig file as secret:
kubectl create secret generic cluster-2-kubeconfig --from-file=kubeconfig.yaml=cluster-2-kubeconfig.yamlCreate the KubernetesCluster resource manifest
cluster-2.yaml:apiVersion: assets.astronetes.io/v1alpha1 kind: KubernetesCluster metadata: name: cluster-2 spec: secretName: cluster-2-kubeconfigDeploy the resource with the following command:
kubectl create -f cluster-2.yaml
Synchronize the clusters
Create the configuration manifest to synchronize the clusters according to the full documentation is provided at Configure LiveSynchronization.
In the following examples there is a minimal configuration to synchronize namespaces labeled with sync=true:
Save the configuration file as
livesync.yamlwith the following content:apiVersion: automation.astronetes.io/v1alpha1 kind: LiveSynchronization metadata: name: active-active spec: plugin: kubernetes-objects-to-kubernetes suspend: false config: sourceName: cluster-1 destinationName: cluster-2 replication: resources: - group: apps version: v1 resource: deployments filters: namespaceSelector: matchLabels: sync: "true" - group: "" version: v1 resource: services filters: namespaceSelector: matchLabels: sync: "true" - group: "" version: v1 resource: secrets filters: namespaceSelector: matchLabels: sync: "true" - group: "rbac.authorization.k8s.io" version: v1 resource: roles filters: namespaceSelector: matchLabels: sync: "true" - group: "rbac.authorization.k8s.io" version: v1 resource: rolebindings filters: namespaceSelector: matchLabels: sync: "true" - group: "" version: v1 resource: serviceaccounts filters: namespaceSelector: matchLabels: sync: "true" nameSelector: excludeRegex: - "^(default|deployer|builder)$" - group: "networking.k8s.io" version: v1 resource: ingresses filters: namespaceSelector: matchLabels: sync: "true"Apply the configuration:
kubectl apply -f livesync.yaml
Operations
Pause the synchronization
The synchronization process can be paused with the following command:
kubectl patch livesynchronization active-active -p '{"spec":{"suspend":true}}' --type=merge
Resume the synchronization
The synchronization process can be paused with the following command:
kubectl patch livesynchronization active-active -p '{"spec":{"suspend":false}}' --type=merge
8.2 - Active-passive Kubernetes architecture
How to setup an active-passive architecture between two Kubernetes clusters
Overview
Active-passive replication between Kubernetes clusters is a strategy designed to provide high availability and disaster recovery, albeit in a more cost-efficient manner than active-active replication.
Prerequisites
- Install Astronetes Resiliency Operator.
- Create a namespace where to store the secrets and run the synchronization between clusters.
Setup
Import the active cluster
Import the first Kubernetes cluster as described in details here:
Save the kubeconfig file as
cluster-1-kubeconfig.yaml.Import the kubeconfig file as secret:
kubectl create secret generic cluster-1-kubeconfig --from-file=kubeconfig.yaml=cluster-1-kubeconfig.yamlCreate the KubernetesCluster resource manifest
cluster-1.yaml:apiVersion: assets.astronetes.io/v1alpha1 kind: KubernetesCluster metadata: name: cluster-1 spec: secretName: cluster-1-kubeconfigDeploy the resource with the following command:
kubectl create -f cluster-1.yaml
Import the passive cluster
Import the first Kubernetes cluster as described in details here:
Save the kubeconfig file as
cluster-2-kubeconfig.yaml.Import the kubeconfig file as secret:
kubectl create secret generic cluster-2-kubeconfig --from-file=kubeconfig.yaml=cluster-2-kubeconfig.yamlCreate the KubernetesCluster resource manifest
cluster-2.yaml:apiVersion: assets.astronetes.io/v1alpha1 kind: KubernetesCluster metadata: name: cluster-2 spec: secretName: cluster-2-kubeconfigDeploy the resource with the following command:
kubectl create -f cluster-2.yaml
Synchronize the clusters
Create the configuration manifest to synchronize the clusters according to the full documentation is provided at Configure LiveSynchronization.
In the following examples there is a minimal configuration to synchronize namespaces labeled with sync=true. The deployments are replicated to the second cluster with replica=0, meaning that the applicatio is deployed but not running in the cluster. Only after the switch to the second cluster, the application will be started.
Save the configuration file as
livesync.yamlwith the following content:apiVersion: automation.astronetes.io/v1alpha1 kind: LiveSynchronization metadata: name: active-passive spec: plugin: kubernetes-objects-to-kubernetes suspend: false config: sourceName: cluster-1 destinationName: cluster-2 replication: resources: - group: apps version: v1 resource: deployments filters: namespaceSelector: matchLabels: sync: "true" transformation: patch: - op: replace path: /spec/replicas value: 0 recoveryProcess: fromPatch: - op: replace path: /spec/replicas value: 1 - group: "" version: v1 resource: services filters: namespaceSelector: matchLabels: sync: "true" - group: "" version: v1 resource: secrets filters: namespaceSelector: matchLabels: sync: "true" - group: "rbac.authorization.k8s.io" version: v1 resource: roles filters: namespaceSelector: matchLabels: sync: "true" - group: "rbac.authorization.k8s.io" version: v1 resource: rolebindings filters: namespaceSelector: matchLabels: sync: "true" - group: "" version: v1 resource: serviceaccounts filters: namespaceSelector: matchLabels: sync: "true" nameSelector: excludeRegex: - "^(default|deployer|builder)$" - group: "networking.k8s.io" version: v1 resource: ingresses filters: namespaceSelector: matchLabels: sync: "true"Apply the configuration:
kubectl apply -f livesync.yaml
Operations
Pause the synchronization
The synchronization process can be paused with the following command:
kubectl patch livesynchronization active-passive -p '{"spec":{"suspend":true}}' --type=merge
Resume the synchronization
The synchronization process can be paused with the following command:
kubectl patch livesynchronization active-passive -p '{"spec":{"suspend":false}}' --type=merge
Recover from disasters
Recovering from a disaster will require the deployment of a TaskRun resource per Task that applies to recover the system and applications.
Define the TaskRun resource in the
taskrun.yamlfile:apiVersion: automation.astronetes.io/v1alpha1 kind: TaskRun metadata: name: restore-apps spec: taskName: set-test-labelCreate the TaskRun:
kubectl create -f taskrun.yamlWait for the application to be recovered.
Understanding the TaskRun
After defining a LiveSynchronization, a Task resource will be created in the destination cluster. The operator processes the spec.config.reaplication.resources[*].recoveryProcess parameter to define the required steps to activate the dormant applications.
This is the Task that will be created according to the previous defined LiveSynchronization object:
apiVersion: automation.astronetes.io/v1alpha1
kind: Task
metadata:
name: active-passive
spec:
plugin: kubernetes-objects-transformation
config:
resources:
- identifier:
group: apps
version: v1
resources: deployments
patch:
operations:
- op: replace
path: '/spec/replicas'
value: 1
filter:
namespaceSelector:
matchLabels:
sync: "true"
For every Deployment in the selected namespaces, the pod replica will be set to 1.
This object should not be tempered with. It is managed by their adjacent LiveSynchronization.
8.3 - Synchronize Zookeeper clusters
How to synchronize Zookeeper clusters data
Overview
In environments where high availability and disaster recovery are paramount, it is essential to maintain synchronized data across different ZooKeeper clusters to prevent inconsistencies and ensure seamless failover.
In the following tutorial will be explained how to synchronize Zookeeper clusters.
Prerequisites
- Install Astronetes Resiliency Operator.
- Create a namespace where to store the secrets and run the synchronization between clusters.
Setup
Import the first cluster
Import the first Zookeeper cluster as described in details here:
Define the Database resource with the following YAML, and save it as
zookeeper-1.yaml:apiVersion: assets.astronetes.io/v1alpha1 kind: Database metadata: name: zookeeper-1 spec: zookeeper: client: servers: - <zookeeper_ip>:<zookeeper_port> - <zookeeper_ip>:<zookeeper_port> - <zookeeper_ip>:<zookeeper_port>Import the resource with the following command:
kubectl create -f zookeeper-1.yaml
Import the second cluster
Import the second Zookeeper cluster as described in details here:
Define the Database resource with the following YAML, and save it as
zookeeper-2.yaml:apiVersion: assets.astronetes.io/v1alpha1 kind: Database metadata: name: zookeeper-2 spec: zookeeper: client: servers: - <zookeeper_ip>:<zookeeper_port> - <zookeeper_ip>:<zookeeper_port> - <zookeeper_ip>:<zookeeper_port>Import the resource with the following command:
kubectl create -f zookeeper-2.yaml
Synchronize the clusters
Create the configuration manifest to synchronize the clusters according to the full documentation is provided here:
In the following example there is the configuration to synchronize every hour all the data in the / path:
Create the synchronization file as
zookeeper-sync.yamlwith the following content:apiVersion: automation.astronetes.io/v1alpha1 kind: SynchronizationPlan metadata: name: synchronize-zookeeper spec: schedule: "0 * * * *" template: spec: plugin: zookeeper-to-zookeeper-nodes config: sourceName: zookeeper-1 destinationName: zookeeper-2 rootPath: / createRoutePath: trueCustom path
The data to be synchronized between clusters can be specified inspec.template.spec.config.rootPath.Apply the configuration:
kubectl apply -f zookeeper-sync.yaml
Operations
Force the synchronization
The synchronization can be run at any time creating a Synchronization object.
In the following example there is the configuration to synchronize all the data in the / path:
- Create the synchronization file as
zookeeper-sync-once.yamlwith the following content:
kind: Synchronization
metadata:
generateName: synchronize-zookeeper-
spec:
plugin: zookeeper-to-zookeeper-nodes
config:
sourceName: zookeeper-1
destinationName: zookeeper-2
rootPath: /
createRoutePath: true
Apply the configuration:
kubectl create -f zookeeper-sync-once.yaml
9 - API Reference
This section contains the API Reference of CRDs for the Resiliency Operator.
9.1 - Assets API Reference
Packages
assets.astronetes.io/v1alpha1
Package v1alpha1 contains API Schema definitions for the assets v1alpha1 API group
Resource Types
AWSS3
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
name string | Bucket name | Required: {} | |
region string | AWS region name | Required: {} | |
secretName string | Secret name where credentials are stored | Required: {} |
Bucket
Bucket is the Schema for the buckets API
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | assets.astronetes.io/v1alpha1 | ||
kind string | Bucket | ||
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
spec BucketSpec |
BucketList
BucketList contains a list of Bucket
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | assets.astronetes.io/v1alpha1 | ||
kind string | BucketList | ||
metadata ListMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
items Bucket array |
BucketSpec
BucketSpec defines the desired state of Bucket
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
generic GenericBucket | Reference a generic bucket | Optional: {} | |
gcpCloudStorage GCPCloudStorage | Reference a GCP Cloud Storage service | Optional: {} | |
awsS3 AWSS3 | Reference a AWS Bucket service | Optional: {} |
Database
Database is the Schema for the databases API
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | assets.astronetes.io/v1alpha1 | ||
kind string | Database | ||
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
spec DatabaseSpec |
DatabaseList
DatabaseList contains a list of Database
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | assets.astronetes.io/v1alpha1 | ||
kind string | DatabaseList | ||
metadata ListMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
items Database array |
DatabaseSpec
DatabaseSpec defines the desired state of Database
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
zookeeper Zookeeper | Zookeeper database | Optional: {} |
GCPCloudStorage
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
name string | Bucket name | Required: {} | |
secretName string | Secret name where credentials are stored | Required: {} |
GenericBucket
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
name string | Bucket name | Required: {} | |
endpoint string | Bucket endpoint | Required: {} | |
useSSL boolean | Use SSL | Optional: {} | |
secretName string | Secret name where credentials are stored | Required: {} |
KubernetesCluster
KubernetesCluster is the Schema for the kubernetesclusters API
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | assets.astronetes.io/v1alpha1 | ||
kind string | KubernetesCluster | ||
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
spec KubernetesClusterSpec |
KubernetesClusterList
KubernetesClusterList contains a list of KubernetesCluster
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | assets.astronetes.io/v1alpha1 | ||
kind string | KubernetesClusterList | ||
metadata ListMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
items KubernetesCluster array |
KubernetesClusterSpec
KubernetesClusterSpec defines the desired state of KubernetesCluster
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
secretName string | Reference to the secret that stores the cluster Kubeconfig | Required: {} |
Zookeeper
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
admin ZookeeperAdmin | Credentials for the admin port | Optional: {} | |
client ZookeeperClient | Credentials for the client port | Optional: {} |
ZookeeperAdmin
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
protocol string | Zookeeper protocol | Required: {} | |
host string | Zookeeper host | Required: {} | |
port string | Zookeeper port | Required: {} | |
secretName string | Zookeeper authentication data | Optional: {} |
ZookeeperClient
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
servers string array | Zookeeper servers | Required: {} |
9.2 - Automation API Reference
Packages
automation.astronetes.io/v1alpha1
Package v1alpha1 contains API Schema definitions for the automation v1alpha1 API group
Resource Types
- Backup
- BackupList
- LiveSynchronization
- LiveSynchronizationList
- Synchronization
- SynchronizationList
- SynchronizationPlan
- SynchronizationPlanList
- Task
- TaskList
- TaskRun
- TaskRunList
Backup
Backup is the Schema for the backups API
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | automation.astronetes.io/v1alpha1 | ||
kind string | Backup | ||
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
spec BackupSpec |
BackupDestinationBucket
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
name string | Reference the Bucket name | Required: {} | |
basePath string | The base path to be used to store the Backup data | Optional: {} |
BackupList
BackupList contains a list of Backup
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | automation.astronetes.io/v1alpha1 | ||
kind string | BackupList | ||
metadata ListMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
items Backup array |
BackupPlugin
Underlying type: string
Appears in:
BackupSourceDatabase
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
name string | Reference the Database name | Required: {} |
BackupSourceKubernetesCluster
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
name string | Reference the KubernetesCluster name | Required: {} | |
namespaces string array | Reference the Kubernetes namespaces to be included | Optional: {} |
BackupSpec
BackupSpec defines the desired state of Backup
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
restartPolicy RestartPolicy | Suspend the CronJob | Optional: {} | |
plugin BackupPlugin | Backup plugin | Required: {} | |
config JSON | Synchronization config | Required: {} |
LiveSynchronization
LiveSynchronization is the Schema for the livesynchronizations API
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | automation.astronetes.io/v1alpha1 | ||
kind string | LiveSynchronization | ||
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
spec LiveSynchronizationSpec |
LiveSynchronizationList
LiveSynchronizationList contains a list of LiveSynchronization
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | automation.astronetes.io/v1alpha1 | ||
kind string | LiveSynchronizationList | ||
metadata ListMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
items LiveSynchronization array |
LiveSynchronizationPlugin
Underlying type: string
Appears in:
LiveSynchronizationSpec
LiveSynchronizationSpec defines the desired state of LiveSynchronization
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
suspend boolean | Suspend the execution | false | Optional: {} |
plugin LiveSynchronizationPlugin | LiveSynchronization plugin | Required: {} | |
config JSON | LiveSynchronization config | Required: {} |
Resource
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
group string | Resource group | Optional: {} | |
version string | Resource version | Required: {} | |
resource string | Resource | Required: {} |
Synchronization
Synchronization is the Schema for the synchronizations API
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | automation.astronetes.io/v1alpha1 | ||
kind string | Synchronization | ||
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
spec SynchronizationSpec |
SynchronizationList
SynchronizationList contains a list of Synchronization
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | automation.astronetes.io/v1alpha1 | ||
kind string | SynchronizationList | ||
metadata ListMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
items Synchronization array |
SynchronizationPlan
SynchronizationPlan is the Schema for the synchronizationplans API
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | automation.astronetes.io/v1alpha1 | ||
kind string | SynchronizationPlan | ||
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
spec SynchronizationPlanSpec |
SynchronizationPlanList
SynchronizationPlanList contains a list of SynchronizationPlan
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | automation.astronetes.io/v1alpha1 | ||
kind string | SynchronizationPlanList | ||
metadata ListMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
items SynchronizationPlan array |
SynchronizationPlanSpec
SynchronizationPlanSpec defines the desired state of SynchronizationPlan
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
schedule string | Schedule in Cron format | Required: {} | |
startingDeadlineSeconds integer | Optional deadline in seconds for starting the job if it misses scheduled time for any reason. Missed jobs executions will be counted as failed ones. | Optional: {} | |
concurrencyPolicy ConcurrencyPolicy | Specifies how to treat concurrent executions of a Job. Valid values are: - “Allow” (default): allows CronJobs to run concurrently; - “Forbid”: forbids concurrent runs, skipping next run if previous run hasn’t finished yet; - “Replace”: cancels currently running job and replaces it with a new one | Optional: {} | |
suspend boolean | Suspend the execution | false | Optional: {} |
template SynchronizationTemplateSpec | Specify the Synchronization that will be created when executing the Cron | Optional: {} | |
successfulJobsHistoryLimit integer | The number of successful finished jobs to retain. Value must be non-negative integer | 2 | Optional: {} |
failedJobsHistoryLimit integer | The number of failed finished jobs to retain. Value must be non-negative integer | 2 | Optional: {} |
SynchronizationPlugin
Underlying type: string
Appears in:
SynchronizationSpec
SynchronizationSpec defines the desired state of Synchronization
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
restartPolicy RestartPolicy | Restart policy | Optional: {} | |
plugin SynchronizationPlugin | Synchronization plugin | Required: {} | |
config JSON | Synchronization config | Required: {} |
SynchronizationTemplateSpec
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
spec SynchronizationSpec | Specification of the desired behavior of the Synchronization | Optional: {} |
Task
Task is the Schema for the tasks API
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | automation.astronetes.io/v1alpha1 | ||
kind string | Task | ||
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
spec TaskSpec |
TaskList
TaskList contains a list of Task
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | automation.astronetes.io/v1alpha1 | ||
kind string | TaskList | ||
metadata ListMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
items Task array |
TaskPlugin
Underlying type: string
Appears in:
TaskRun
TaskRun is the Schema for the taskruns API
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | automation.astronetes.io/v1alpha1 | ||
kind string | TaskRun | ||
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
spec TaskRunSpec |
TaskRunList
TaskRunList contains a list of TaskRun
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | automation.astronetes.io/v1alpha1 | ||
kind string | TaskRunList | ||
metadata ListMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
items TaskRun array |
TaskRunSpec
TaskRunSpec defines the desired state of TaskRun
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
taskName string | Task name | Required: {} |
TaskSpec
TaskSpec defines the desired state of Task
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
restartPolicy RestartPolicy | Restart policy | Optional: {} | |
plugin TaskPlugin | Task plugin | Required: {} | |
config JSON | Task config | Required: {} |